
Drug discovery is a complex process. For a scientist, the goal is to identify targets (genes) that are involved in the development of a disease.
The discovery of targets requires a great deal of exploration of existing biomedical literature (millions of papers, patents, clinical trials and databases), and inference of new relationships between biomedical entities. This is an ambitious task for a scientist alone. To address this problem, we have developed machine learning methods to improve the way scientists make sense of huge amounts of data and discover non-obvious relationships between genes, diseases and molecules, based on existing relationships.
Extracting facts from the biomedical literature that are usable for real-life applications, such as drug discovery, is a very challenging task. If done manually, it is simply not possible for scientists alone to read and process the whole corpus of biomedical information. If we use unsupervised methods (e.g. OpenIE), the relevance of the extracted relations will not be guaranteed, because emerging patterns do not necessarily align with the scientist’s requirement. Finally, if we use a supervised method, we need labeled data (e.g. a list of curated entity pairs or positive/negative examples of sentences expressing relationships) which are often scarce or not appropriate for the given use case.
To address these issues, we have created a new method, interpret. The system extracts existing facts without requiring any training data or hand-crafted rules. Instead, it discovers and recommends patterns rather than prescribing them.
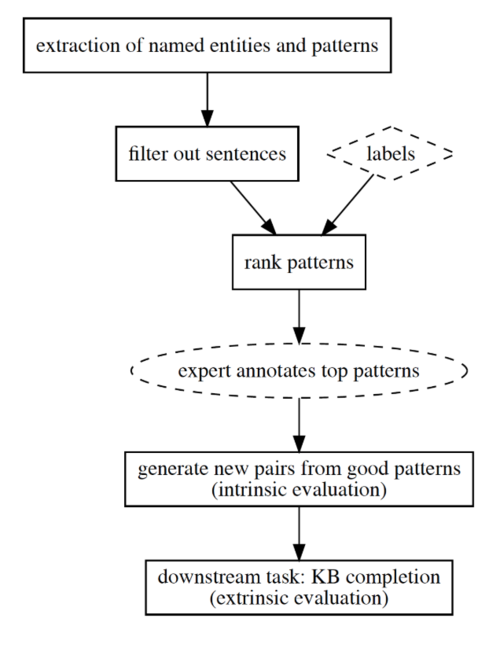
We start by extracting interpretable patterns from sentences (see workflow diagram on the right). This is a totally automated process which is done solely using unstructured data from the biomedical corpus. We discover patterns such as “role of GENE in DISEASE”, “GENE target for DISEASE” or “DISEASE caused by GENE mutation”. We then ask our drug discovery scientists to validate which patterns best describe the relationships of interest. Within minutes, they are able to identify patterns that can be used to retrieve thousands of new facts. As an example, the following sentence was surfaced as supporting the top pattern and provides a clear therapeutic relationship between gene “IL10” and disease “lupus nephritis”: “This proves the importance of IL10 in the pathogenesis of lupus nephritis.”
The interpret method is, by design, easily transferable to other types of biomedical entities. Types of relationships can be extended to complex “n-ary” relationships involving multiple entities e.g. "knockdown of GENE affects DISEASE in TISSUE".
Interpret allows drug discovery scientists to generate relevant new pairs for application very rapidly. We also show that the addition of these new pairs can improve the precision of a downstream knowledge base completion task which is used to infer novel biomedical facts beyond what is reported in the literature and improve the likelihood of discovering novel targets.
Back to blog post and videos


