
This post examines a straightforward way of running a parallel pipeline with the resources at hand, using a simple and established tool: Make.
Processing small (100s of megabytes) to large (terabytes) volumes of data is frequently necessary during development. And quite frequently in rapidly evolving projects, the required infrastructure to run these is not present, difficult to deploy against, or simply not ready yet. But we do have access to a multicore machine - anywhere from a local laptop to a 30-core blade.
Having worked with subject matter experts in multiple domains, ranging from healthcare, finance, machine learning or statistics, a recurring theme one notices is the need to process large amounts of data during development using different infrastructures: in-house distributed systems, PySpark, hadoop, or plain ol' large machines. Often it can be quite time-consuming to do rapid prototyping or fast development while using these systems, or it could even be the case that these pieces of infrastructure aren't even deployed yet. A consistent challenge has been the need to do so while using code written in R, Python, Java, or perl.When these situations occur, the Unix Philosophy comes to mind: The data pipeline under development should be up and running quickly, it needs to be modular, and it should use text streams or file systems to pass data between modules. This is where Make comes into play.
One could easily think "Wait What? Make? That really old C build tool? "
That is a fair question. Plenty of good pipeline tools exist for large datasets, yet one will surely find themselves in a scenario without such tools. A scenario where no one maintains a PySpark cluster, or maintains an AirFlow deployment, or translates the code out of scala. One common scenario in research and cross functional domains is where a core contributor may not be a software engineer, yet they understand enough of their code such that they can read a file in, process it, and write a file out. Make helps in these scenarios to create an appropriately abstracted *simple* data pipeline that becomes very easily parallelizable, and indeed, even extendable.
This post aims to help you use Make to set up a simple pipeline that can be iterated. When the data pipeline is then up and running, a simple design abstraction will exist that can port to a more appropriate infrastructure.
Why use Make?
There are many tools that perform pipeline processing, but a comparison of tools is beyond the scope of this document. However, there are a few positives for using Make:
- Ubiquity - almost all machines you use have it or have it via some code repository.
- Maintenance - You don’t need to set up a large cluster and have it maintained.
- Draft Development - Because it is fast to get feedback, you can design your data pipelines quickly and check that the core modules are functioning before moving to a more powerful tool.
- Shell - Using the Unix Philosophy and linking programs together enables you to very quickly put together programs written in different languages.
- Simple - the conceptual framework of a dependency graph is well defined in Makefiles.
Background
Map Reduce
Map Reduce is a well-known technique for parallel processing. It’s most useful for distributing jobs among large clusters with many distributed resources. But we don’t always need large hadoop clusters to get the benefit of the paradigm.
Make
Make is one of the greatest programs in the *nix ecosystem. It’s been in active development for over forty years, meaning that it does its job really, really, well.What is its job? Most people know it as a build tool for compiling C programs, or perhaps as a way of tracking small aliases in a directory for functions like ‘install’ or ‘clean’. But more fundamentally, its job is to be a scheduler.
Features of Make Important for Pipelines and Map Reduce:
- Dependency Graph - It ingests a Directed Acyclic Graph of rules known as a Makefile
- Topological Order of Rule Execution - it executes rules in topological order; meaning all the prerequisite rules are executed first. The target rules are executed if and only if the prerequisites have completed successfully.
- Smart Restart of Rule Execution - If a large pipeline needs to restart, it will only execute rules with modified dependencies, meaning it will NOT execute rules that have already run.
We can spend a lot of time getting into the what, why, and how, but let’s make this a practical tutorial, for now, to get us up and running for Map Reduce in Make.
Make and Makefiles Refresher
Make has a long history and excellent documentation at the GNU Make website. But to make the following tutorial more digestible, we will refresh some basics about Make here.
A Rough Sketch of Make
- make executes the dependency graphs defined in Makefiles
- Makefiles are made up of rules, which define a rule’s target, the rule’s prerequisites, and the recipe that updates the target
- When we call make from the command line, we’re giving it a make goal to update
- make will execute all rules in the required order to satisfy the goal
- make will skip rules that already have completed targets
Variables
Variables are assigned using the = operator. Convention is that variable names are all caps because they’re considered to be constants. They are defined at the beginning of make execution and do not change during each call to make. We can also pass variables to make via the command line.
Special Variables
Special variables help us create reusable recipes:
- $@ -> the target rule
- $< -> the first normal prerequisite
- $^ -> all normal prerequisites, (we'll use this later)
- $| -> all order-only prerequisites (we’ll use this later)
Phony Targets
In unix, Everything is a File, and it’s helpful to remember that targets are files as well. However, for Make Reduce, we can have a convention: If a target does not have a file extension, then it does not represent a file to be updated. It’s known as a Phony Target, it’s simply a name for the recipe that will be executed.
Make Reduce Tutorial
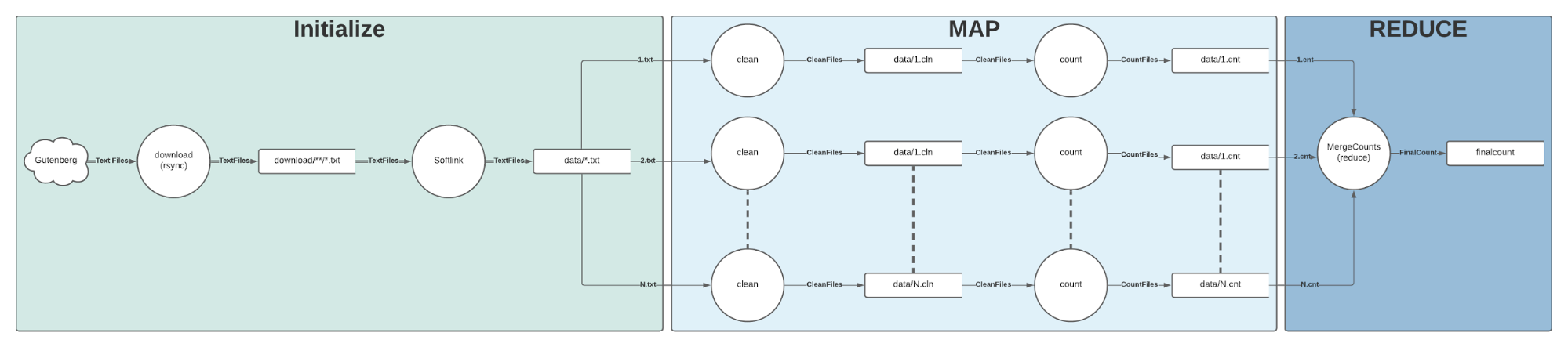
We will work with a typical example of Map Reduce: word counting.
Goal: Count all of the unique words in some group of text files.
Pipeline Plan:
1. We will grab some text files from gutenberg (initialization)
2. We will clean each text file (map)
3. We will count the words in each cleaned file (map)
4. We will sum up all of the counted words and merge them together (reduce)
The tasks above marked with (map) are considered obviously parallel: task 2 can operate on each file independently; the cleanliness of each file in task 2 is irrelevant to the cleanliness of every other file in task 2. Task 3 is also obviously parallel in that the word count for each file is irrelevant to every other file in task 3. Finally, the reduce step adds up everything and outputs a count file.
Makefile
Pipeline Step 1: Initialize
We can now begin building our Makefile. We’ll start with a few initialisation variables: what directory our source text files will be downloaded to, and what directory our work will be stored in.
We’ll start with a simple rule, init, to initialise and download. We want our rule’s recipe to do the following:
- Create the necessary directories for workspaces if they do not exist
- Download all the text files required
- Soft link all the text files to a single directory for simpler viewing.
We'll be downloading files from Project Gutenberg . In order to follow their robot policy, we'll rsync files from a mirror at aleph.gutenberg.org. The LIMITSIZE variable allows us to download only about 1000 files by limiting the files available for download to 100kb-105kb. If we set the LIMITSIZE variable blank, we will download all ~100,000 serially and it could take an hour or so.
To execute the initialisation rules, run the following command:
$ make init
In this command, we’ve told make that our goal is to create or update the ./make_reduce/data directory. make reviews the dependency graph in the Makefile, then topologically sorts and determines the correct order of operations and then executes all the recipes required. We’ve fed it a graph and it is executing it for us!
Once it completes, you should see something similar to the output below: We have downloaded all the files and then soft linked them:
# Shell
$ make init
...
sent 1506636 bytes received 51176104 bytes 1300808.40 bytes/sec
total size is 43554701990 speedup is 826.74
$ mkdir -p /Users/meerkat/workspace/make_reduce/data
$ find /Users/meerkat/workspace/make_reduce/download -name '*.txt' \
-exec ln -sf {} /Users/meerkat/workspace/make_reduce/data \;
It is a little messy because it follows the directory hierarchy from gutenberg, which is why we soft linked all the .txt files to a single directory.
# Shell
$ ls -l ./make_reduce/data | head -4
...
lrwxr-xr-x 1 meerkat 92 Sep 14 11:41 10133.txt -> ./make_reduce/download/1/0/1/3/10133/10133.txt
lrwxr-xr-x 1 meerkat 92 Sep 14 11:41 10141.txt -> ./make_reduce/download/1/0/1/4/10141/10141.txt
...
And the files count:
# Shell
$ ls ./make_reduce/data | wc -l
1070
We have about 1000 text files that we want to perform a word count on. Here is the first 10 lines of The Vigil of Venus and Other Poems by “Q”:
# Shell
$ head ./make_reduce/data/10133-8.txt
Project Gutenberg's The Vigil of Venus and Other Poems by "Q"
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included
with this eBook or online at www.gutenberg.net
Title: The Vigil of Venus and Other Poems by "Q"Pipeline Step 2: Clean Text File
Let’s create a function that might make a data scientist a bit more comfortable. We’ll write our clean function in python, and have the recipe execute it from the shell.
Below is our python script for cleaning text files. First, it reads a file into memory, lowercases all characters, removes all punctuation, and removes any tokens that are less than three characters long. It then outputs the cleaned text file with one word per line into an output file:
Let’s encode the clean step into our Makefile using the following strategy:
- Use the wildcard function to assign a list of input file paths into a variable.
- Use string substitution to create a list of output file paths.
Create a Match-Anything Pattern Rule which links each input file name to the output filename.
$ make clean
We can see the creation of the *.cln files in our WORK_DIR
# Shell
$ head ./make_reduce/data/10133-8.cln
project
gutenbergs
the
vigil
venus
and
other
poems
this
ebookAside: Parallelization
Each pair of *.txt and *.cln files are independent of each other pair. This means that they have now become obviously parallel. make has a critical directive that we can pass from the command line to process each of the independent targets in parallel: -j. -j or --jobs tells make how many jobs to run in parallel. We can say -j 4, which will process 4 jobs at a time, or we can just pass -j without the number of jobs and make will process as many jobs as cores are available.
Below is the GNU Time output from running make clean in serial - one job at a time. It took about 1 minute to process 1000 files on a standard laptop.
# Shell
35.29user 10.80system 0:51.19elapsed 90%CPU (0avgtext+0avgdata 9880maxresident)k
0inputs+0outputs (511major+2975605minor)pagefaults 0swaps
When running make -j next, it will parallelise as much as possible. If you would like to try, you will need to delete the *.cln files so that make knows to remake them.
$ make clean -j
Below is the GNU Time output from running make -j with 6 cores. It took about 12 seconds - a 4x speed up
# Shell
59.50user 16.52system 0:12.60elapsed 603%CPU (0avgtext+0avgdata 10092maxresident)k
0inputs+0outputs (63major+3022553minor)pagefaults 0swaps Pipeline Step 3: Count words in each file
Each of the *.cln files need to be counted. We’ll use simple BASH commands for this task:
We will repeat the steps that we did with clean. You should notice a small difference in the rule to create *.cnt files: We have added the executable count_cln.sh as a prerequisite. Why? Because if we change our count function, make will automatically rerun our count step! We will automatically restart parts of the pipeline only from the steps that have either new data or a new function. We change our special variable from $< to $^ so that all normal prerequisites are passed to the recipe.
$ make count -j
Once we run make count -j we should see *.cnt files with unique counts for each word:
# Shell
$ head ./make_reduce/data/10133-8.cnt
1000 the
498 and
161 with
157 you
147 her
119 that
112 for
94 not
93 his
93 butPipeline Step 4: Reduce
Now that we have cleaned and counted all of the words and put them into their own files, we need to perform the reduce step. We will use our $^ variable again to pass in all of the normal prerequisites to the recipe.
$ make count -j$ make reduce$ head ./make_reduce/finalcount
1038177 the
499847 and
162986 that
147897 you
147390 with
127524 for
118562 was
109614 this
103130 his
91695 notExecute Entire Pipeline with a Single Command
We have been executing these steps individually to understand how each one works. Now let’s put them all together in their own phony target. We will define a goal pipeline that will execute all of the make commands recursively from the shell using the special variable $(MAKE). We can set our parallel parameters with the -j directive, and end with the reduce.
$ make pipeline
If you’ve been following the commands, the make pipeline command will probably let you know that everything is complete. That’s okay. We can force it to execute a couple of different ways: passing a new WORK_DIR variable or the force directive -B
$ make pipeline WORK_DIR=/usr/local/data/make_reduce/gutenberg$ make pipeline -BScale
We have also been playing with some sample files - approximately 1000. When we ran it on a standard laptop, it ran in about a minute after the initial download. Not bad. But if we want to see what happens when we run against all 100,000 text files of the gutenberg, we need to change the LIMITSIZE variable. This means that the initialisation step of downloading all of the data is the bottleneck. Rsync will help us reduce duplicate downloads. However, once the initial download is complete, then we will be able to execute on a much much larger dataset.
$ make pipeline WORK_DIR=/usr/local/data/make_reduce/gutenberg LIMITSIZE=”” -BCode Appendix
Makefile
clean.py
count_cln.sh
Back to blog post and videos


